저장소 패턴
저장소 패턴은 데이터 저장소를 더 간단히 추상화한 것으로 이 패턴을 사용하면 모델 계층과 데이터 계층을 분리할 수 있다.
애자일 방식으로 작업할 때는 최소 기능 제품(MVP:Minimum Viable Product) 을 만드는 것이 우선이다. 1장에서 만든 도메인 모델을 API 로 만든다고 하면, API 가 MVP 가 된다.
장고의 MVC(모델-뷰-컨트롤러) 구조처럼 표현 계층 -> 비즈니스 로직 -> 데이터베이스 계층으로 구성된 계층 아키텍처가 존재한다. 각 계층이 자신의 바로 아래 계층에만 의존하게 만드는 것이 이 계층 아키텍처의 목표다.
하지만 도메인 모델에는 그 어떤 의존성도 없어야 한다. 즉, 하부 구조와 관련된 문제가 도메인 모델에 지속적으로 영향을 끼치면 안된다. 대신 모델을 마치 계층 내부에 있는 것으로 간주하고, 의존성이 내부로 들어오게 만들어야 한다.
표현계층 -> 비즈니스 로직 <- 데이터베이스 계층
이런 방식을 양파 아키텍처(onion architecture) 라고 부른다.

앞서 1장에서 봤던 이 모델을 데이터베이스로 만들어야 한다.
일반적으로 ORM(object-relational-mapping) 을 사용한다. ORM 이 제공하는 가장 중요한 기능은 도메인 모델이 데이터를 어떻게 적재하는지에 대해 알 필요가 없다는 것이다. 즉, ORM 을 통해서 특정 데이터베이스 기술에 도메인이 직접 의존하지 않도록 할 수 있다.
그러나 일반적인 코드를 보면 아래와 같이 이미 각 모델의 속성이 데이터베이스의 컬럼과 직접적인 연관이 있다.
from sqlalchemy import Table, Column, Integer, String, ForeignKey
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.orm import relationship
Base = declarative_base()
class Order(Base):
id = Column(Integer, primary_key=True)
class OrderLine(Base):
id = Column(Integer, primary_key=True)
sku = Column(String(250))
qty = Column(String(250))
order_id = Column(Integer, ForeignKey('order.id'))
order = relationship(Order)이는 모델이 전적으로 ORM에 의존하고 있다. 반대로 ORM이 모델에 의존하게 해야 한다.
스키마를 별도로 정의하고, 스키마와 도메인 모델을 상호 변환하는 명시적인 mapper를 정의하는 것이다.
from sqlalchemy import Table, MetaData, Column, Integer, String, Date, ForeignKey
from sqlalchemy.orm import mapper, relationship
import model
metadata = MetaData()
order_lines = Table(
"order_lines",
metadata,
Column("id", Integer, primary_key=True, autoincrement=True),
Column("sku", String(255)),
Column("qty", Integer, nullable=False),
Column("orderid", String(255)),
)
...
def start_mappers():
lines_mapper = mapper(model.OrderLine, order_lines)ORM이 도메인 모델을 임포트한다. 반면, 도메인 모델은 ORM을 임포트하지 않는다. 또한 SQLAlchemy가 제공하는 추상화 객체를 사용해 테이블과 열을 정의한다. mapper 함수는 호출될 때, 사용자가 따로 정의한 도메인 클래스와 테이블을 연결한다.
결과적으로 start_mapper 함수를 호출하면 도메인 모델과 데이터베이스에 저장하거나 불러올 수 있다. 그러나 이를 호출하지 않으면 도메인 모델 클래스는 데이터베이스를 인식하지 못한다.
이러한 구조를 사용하면 ORM 의 이점을 취하는 동시에, 도메인 클래스를 사용해 질의를 쉽게 명확하게 할 수 있다.
저장소 패턴은 저장소를 추상화한 것이다. 저장소 패턴은 모든 데이터가 메모리상에 존재하는 것처럼 가정한다.
import abc
import model
class AbstractRepository(abc.ABC):
@abc.abstractmethod
def add(self, batch: model.Batch):
raise NotImplementedError
@abc.abstractmethod
def get(self, reference) -> model.Batch:
raise NotImplementedError
class SqlAlchemyRepository(AbstractRepository):
def __init__(self, session):
self.session = session
def add(self, batch):
self.session.add(batch)
def get(self, reference):
return self.session.query(model.Batch).filter_by(reference=reference).one()
def list(self):
return self.session.query(model.Batch).all()일반적인 저장소 패턴은 위와 같다. 저장소 패턴의 역할은 애플리케이션에서 도메인 모델 객체를 통해 실제 데이터베이스와 통신하는 중간 단계 역할이다.
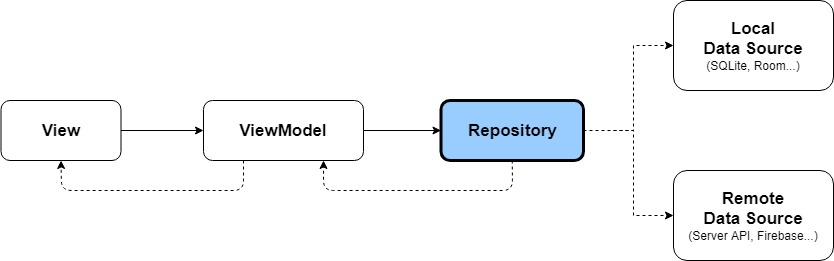
위와 같이 데이터베이스와 도메인 객체를 분리하여, 애플리케이션 단계에서 DB와 관련한 인프라를 신경쓸 필요가 없다. 도메인 모델 객체를 사용하므로 보다 간결하고 제어 가능한 코드를 구성할 수 있다. 또한 테스트를 위한 Fake 저장소를 만들기도 쉽다. 단, 유지보수 측면에서 비용이 증가하고, 저장소 패턴을 모르는 개발자의 경우 일관된 패턴의 흐름을 깨는 팩터가 추가될 수 있다.
참고 : https://0391kjy.tistory.com/39
Repository Pattern 이해하기
Repository Pattern? Repository(리포지토리) 패턴은 디자인 패턴 중 하나로, 데이터가 있는 여러 저장소(Local, Remote)를 추상화하여 중앙 집중처리 방식을 구성하고, 데이터를 사용하는 로직을 분리시키기
0391kjy.tistory.com
'python' 카테고리의 다른 글
| Architecture Patterns with Python(3장) (0) | 2021.10.23 |
|---|---|
| Fluent Python (챕터 5) (0) | 2021.10.22 |
| Fluent Python (챕터 4) (0) | 2021.10.11 |
| Fluent Python (챕터 3) (0) | 2021.10.09 |
| Architecture Patterns with Python(1장) (0) | 2021.10.09 |
